On the internet, anyone can publish whatever they like in any format they desire. This is surely a good thing, but unstructured data can be hard to make sense of, compare, or analyse.
Many times it can be easier to extract data from a website into your own system to sort and query. If a website provides an API then you should use that, but if they don’t, web scraping might be the way to go.
What is web scraping?
When a human looks at a website, they can easily tell what the different parts of it represent. For example, here’s some running shoes listed on AliExpress.
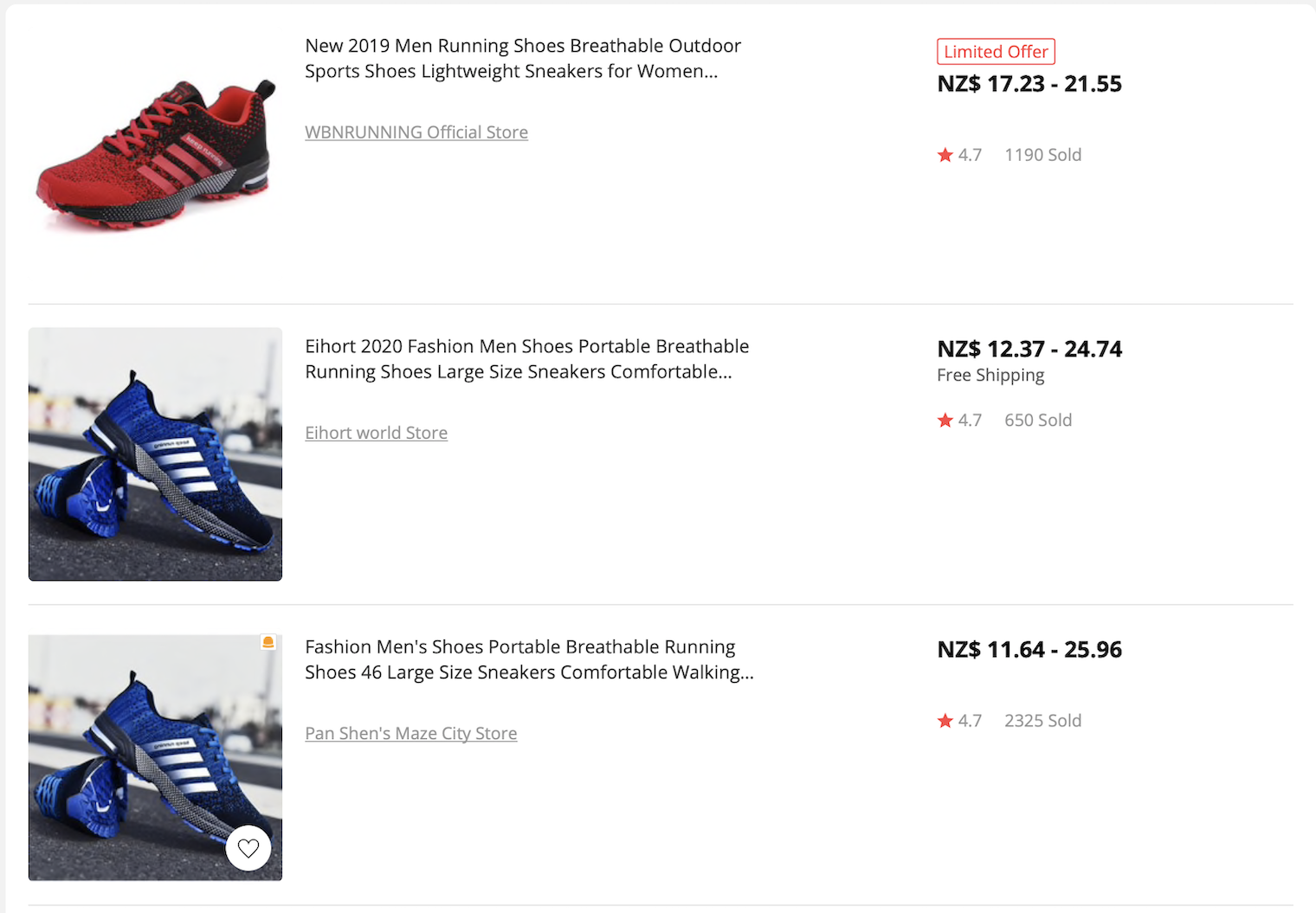
The main pieces of data for each listing are the product image (on the left), product description (in the centre) and price (on the right).
For comparison, here’s a screenshot of shoe listings on Asos.
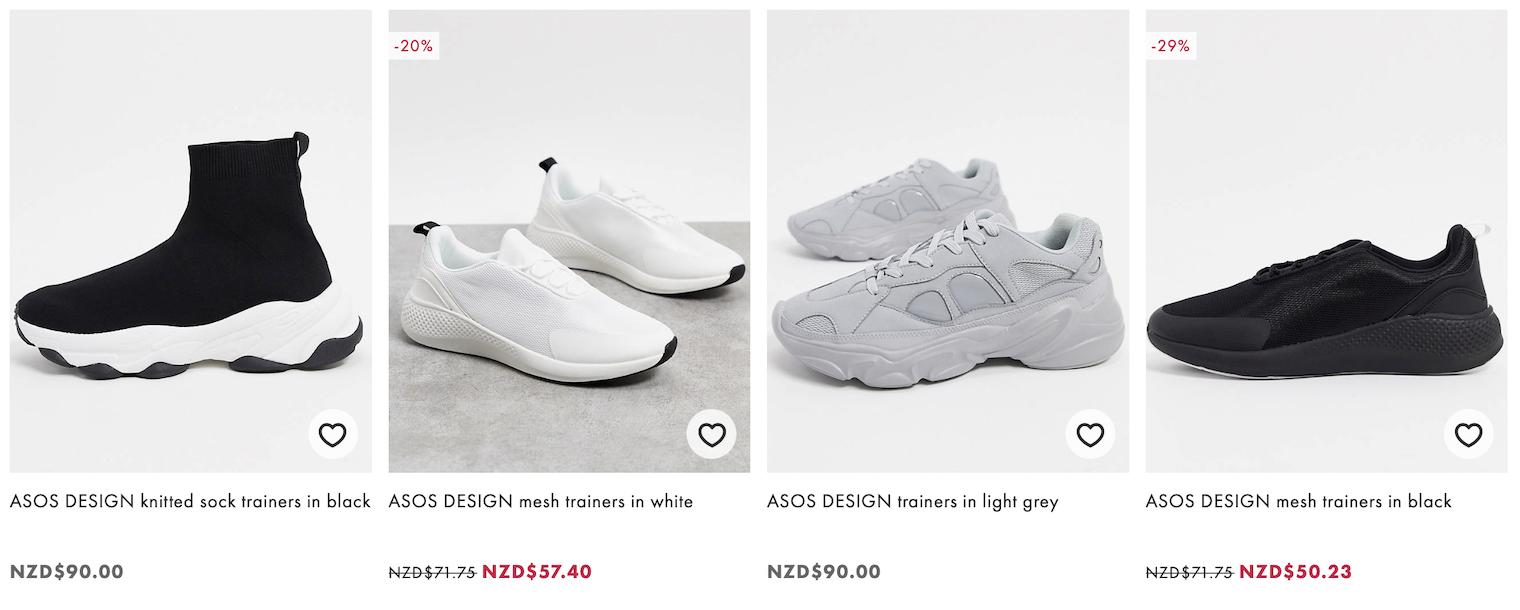
The product image is the top, description in the middle, and price on the bottom.
Although it’s a completely different layout, humans can easily work out the data features. We can open up different stores in different browser tabs and compare products between them.
Computers aren’t so smart. If we wanted to have a computer do this comparison, first we need to tell it how to extract the data from each retailer’s site. We need to tell it where on each page to find the data. We could then put the data into a database in a normalised format and perform our own comparison.
The tool that extracts the information is a web scraper and this whole process is called web scraping.

Why web scrape?
I’ve mentioned one use case which, is normalising and comparing products from different web sites, but there are many other things you can do with web scraping:
- Periodically download a page and check for changes.
- If a site doesn't have a search function, scrape it and search in your own database.
- Archive sites that might not be around forever.
- Remix data from different sites for analysis.
Some of these could be performed just once, others might be done regularly, either manually or automatically.
Here are a few concrete examples of the above suggestions.
Site Monitoring
This is quite a common use of web scraping: periodically fetching a page and looking for changes. It’s like having your own virtual assistant hitting Refresh 24 hours a day.
The use cases are almost endless. You could be notified:
- When a news article containing a specific word is posted on a site
- If the content of a page doesn't change after a specified amount of time
- When new jobs, items, concert tickets, etc, are posted to a site
- When your University grades are updated
- If your bank balance reaches a certain level
Scraping can also take over tedious tasks like link checking. A scraper can periodically go through your site and check that all the links still go to valid pages. It could even send test emails to any email addresses you have listed to make sure they don’t bounce, or submit web forms and make sure no errors occur.
Just about anything you can do online, you can automate and send a notification, using web scraping.
Custom Searching
Some web sites have poor search functionality. A web scraper can go through each page on a target site and save information to a local database. You could query your new database manually, export all the data as a CSV for use with Excel, or even build your own web frontend for in-house use.
Archival
Websites won’t be around forever. You might want to keep a copy around for reference long after the site is gone. Maybe there’s a forum thread you’ve been following for a while, and it has all sorts of useful information being posted. You can periodically scrape and download its content so that if it disappears you still have it for reference if you need.
Data Remixing
As was mentioned in the opening paragraph, web scraping can allow you to take data from different sources (like multiple sites) and normalise it.
For ten years, Deal Shrimp combined data from many different New Zealand Daily Deal sites. Different sites had different types of data for products, such as how the discount was presented, what region it was available in and so on. I built Deal Shrimp to normalise this data into a common format that could be presented consistently to users.
You can also scrape data for scientific analysis, including combining different data sets from different web sites.
Is web scraping allowed?
Web scraping itself is not illegal. For example, you can scrape your own site(s) without getting into any issues. And search engines like Google (and others) build their business on web scraping.

The questions to consider when scraping sites you don’t own are:
Are you causing performance problems?
Depending on how fast you’re trying to crawl a web site, you may be causing it to slow down. Most big sites can handle heavy loads but smaller ones may not be able to.
Site administrators can use the Crawl-delay directive to instruct scrapers on how quickly they should crawl, and your scraper should honour this (some scraping frameworks obey it automatically). If you don’t you may find your scraper getting banned.
How are you using the data?
You’re more likely to be OK with web scraping if you’re only using the scraped data for personal or company-internal purposes. That is, data you scrape is stored in your own database and not republished elsewhere – just because you can scrape and download videos from YouTube doesn’t mean you can host them on your own website.
It is also important to consider how the site might feel about the use of their data. The Daily Deal sites featured on Deal Shrimp were happy to be scraped. Many reached out and asked to be featured, as it meant more traffic being driven to their site.
Is it against the terms of service?
A web site may explicitly forbid scraping in its terms of service, but even if it doesn’t, you might still not be allowed to scrape it. If the site requires a user to manually accept a terms of service before using it, then you shouldn’t make the data behind that terms of service accessible – since you’d be making it available without your users accepting the original site’s terms.
Here’s an article called Web scraping is now legal, outlining a judgement of LinkedIn vs HiQ, an analytics company. It dives into the above issues in more detail.
Web Scraping Experience
Now that you know about web scraping, hopefully you’ve got some great ideas on how to utilise it to help your business.
At Tera Shift we have over a decade of web scraping experience, and have implemented bespoke solutions for customers similar to the examples above. From single page monitoring, to multi-site comparison tools and broad data crawls, our web scraping experience is extensive.
We’ve encountered and dealt with many of the obstacles that can come with web scraping and can help build a solution for you.